7.5 Confidence and Prediction Intervals for specific values of \(X\)
If you have a new data point (and we’re going to use DC here), you can easily generate confidence and prediction intervals for this point using the function predict():
First let’s look at the DC voting values:
print(DC)## # A tibble: 1 x 6
## State ST Y.2004 Y.2008 Y.2012 Y.2016
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Washington DC DC 0.89 0.92 0.91 0.91Notice that the proportion of Democratic voters in the 2012 election for DC (0.91) is far outside the observed range in the 50 states. We need to be particularly careful about making predictions for this point because we would be extrapolating beyond the range of the data used to fit the model.
We can use the predict() function to get the confidence and prediction intervals for the conditional value of \(Y | X =\) 0.91:
(for more info on this function, use ?predict.lm)
The 95% confidence interval for the expected value of the 2016 vote given this 2012 vote value, \(\mu_y\) | \(X =\) 0.91:
predict(lin.model, newdata = DC,
interval = "confidence", level = 0.95)## fit lwr upr
## 1 0.844835 0.8061764 0.8834937The 95% prediction interval for any specific point given this 2012 vote value, \(\widehat{y}_i\) | \(x =\) 0.91:
predict(lin.model, newdata = DC,
interval = "prediction", level = 0.95)## fit lwr upr
## 1 0.844835 0.7705959 0.9190742Discussion
- Is there much difference between the confidence and prediction intervals in this case? (Why, or why not)?
- Is DC inside the prediction interval?
- Is DC consistent with the association summarized by the regression model for the 50 states?
- Do you think DC would be an influential point if we included it in the regression?
- Does it make sense to ask whether the specific observation DC is inside the confidence interval? (Why or why not?)
We can also plot the 95% confidence and prediction interval bands for the regression line.
# set up vector of equally spaced x values across the possible range
new.values <- data.frame(Y.2012=seq(0, 1.0, by=0.05))
conf_interval <- predict(lin.model, newdata = new.values,
interval = "confidence", level = 0.95)
pred_interval <- predict(lin.model, newdata = new.values,
interval = "prediction", level = 0.95)
plot(Y.2016 ~ Y.2012, data = election50, type="n",
xlim=c(0,1), ylim=c(0,1),
xlab = "2012 Election", ylab = "2016 Election",
main = "Proportion of Votes for Democratic Candidate By State")
DescTools::DrawBand(y = pred_interval[, 2:3],
x = new.values[,1], col = "grey90")
DescTools::DrawBand(y = conf_interval[, 2:3],
x = new.values[,1], col = "grey80")
points(Y.2016 ~ Y.2012, data = election50, col = "blue")
text(Y.2016 ~ Y.2012, data = DC, labels = "DC", cex=.6, col = "red")
abline(lin.model, col = "blue")
legend("topleft",
legend=c("Prediction interval", "Confidence Interval"),
pch=15, col=c("grey90", "grey80"))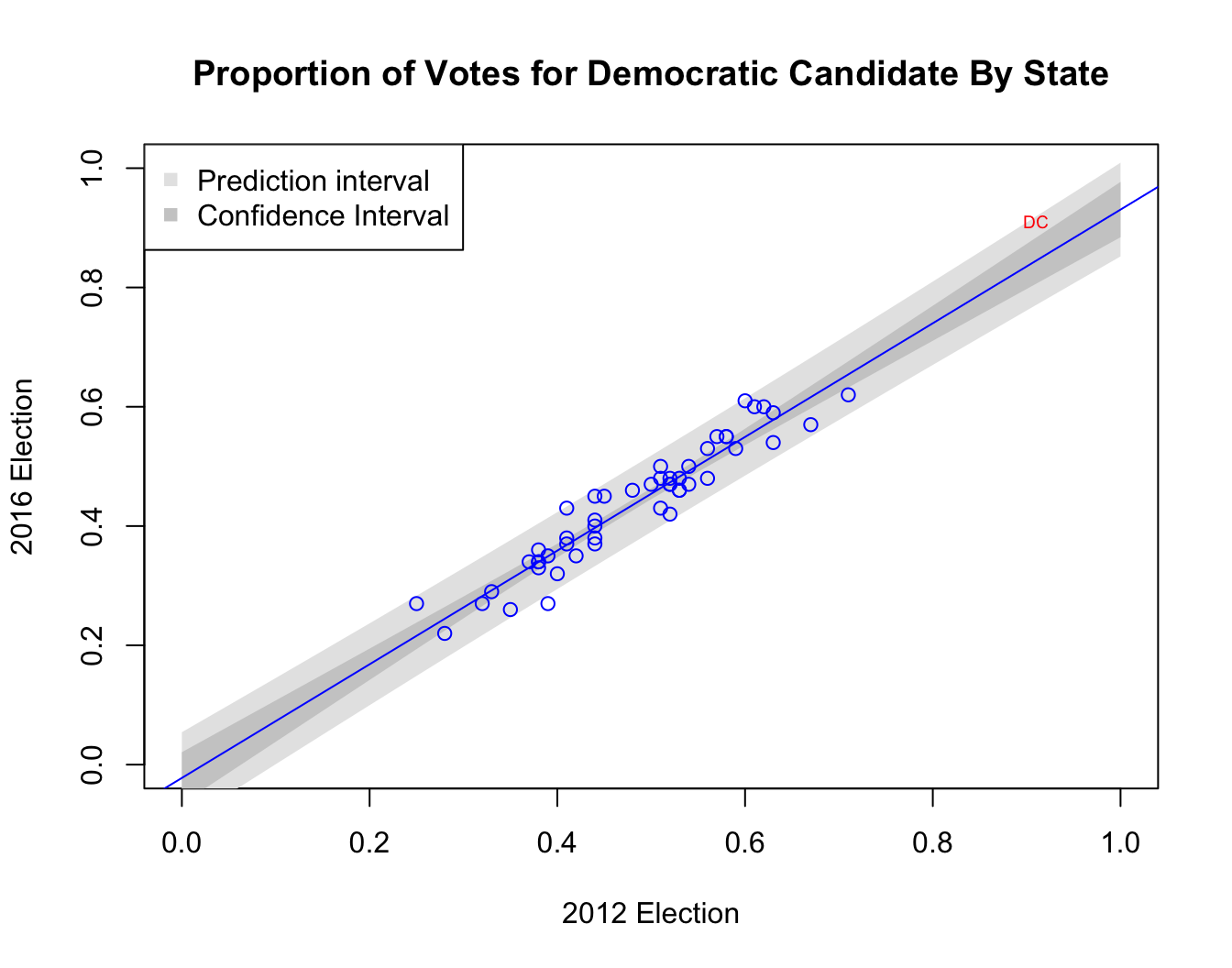
The confidence interval for \(\left(\widehat{y} \mid x\right)\) represents how the uncertainty in our estimate of the regression coefficient (the slope of the regression line) influences our prediction at specific values of \(x\).
The prediction interval is larger. This is because it accounts for both uncertainty of the regression line, and the the residual variation around the line.
Both intervals are nonlinear and grow wider as the prediction point gets farther from \(\overline x\).