7.1 Linear Regression
Consider the simple linear model \[Y_i = \beta_0 + \beta_1 X_i + \varepsilon_i\]
where \(Y_i\) and \(X_i\) are the proportion of democratic voters in 2016 and proportion of democratic voters in 2012 of the \(i^{th}\) state respectively, for \(i = 1, \dots , 50\) (not including DC); \(\beta_0\) is the intercept; \(\beta_1\) is the slope; and \(\varepsilon_i \sim \mathcal N(0, \sigma^2)\), \(i = 1, \dots, 50\), are i.i.d. normal errors. We might expect the proportion of Democratic voters in 2012 to be highly correlated to the proportion of Democratic voters in 2016.
lin.model <- lm(Y.2016 ~ Y.2012, data=election50)
lin.model##
## Call:
## lm(formula = Y.2016 ~ Y.2012, data = election50)
##
## Coefficients:
## (Intercept) Y.2012
## -0.02235 0.95295- How do you interpret the value of the slope coefficient?
- What about the intercept?
To see what output is stored in the object lin.model, use the names function:
names(lin.model)## [1] "coefficients" "residuals" "effects" "rank"
## [5] "fitted.values" "assign" "qr" "df.residual"
## [9] "xlevels" "call" "terms" "model"You can extract these object elements, or pass them to other functions.
For example, the abline function will automatically pull the coefficients from the lin.model object and plot the corresponding line. The fitted.values in this object are our \(\hat{Y}_i\)’s, and we can plot them as well.
plot(Y.2016 ~ Y.2012, data = election50,
main = "Proportion of Votes for Democratic Candidate By State",
xlab = "2012 election", ylab = "2016 Election",
pch = 1, col = "blue",
ylim=range(lin.model$fitted.values, Y.2016))
abline(lin.model, col = "red")
points(lin.model$fitted.values ~ election50$Y.2012,
pch = 2, col = "red")
legend("topleft", legend = c("Observed", "Fitted"),
pch = c(1,2), col = c("blue","red"))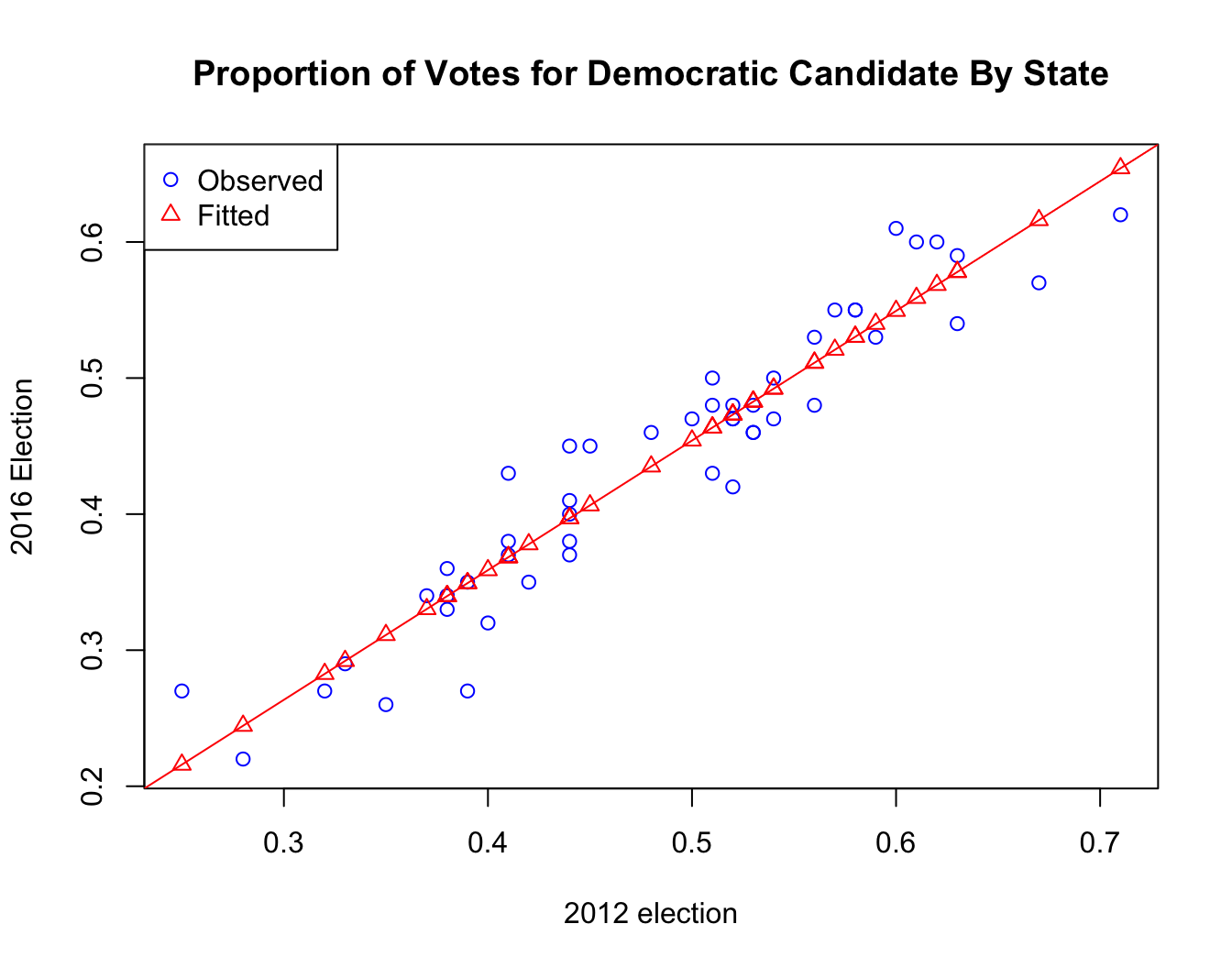
Discussion
- What observations are you able to draw from the plot?
- What assumptions do we need for linear regression? Do you think they are satisfied here?
- Are there any outliers?
- Are there any influential points?
The summary() function is a very useful function in R for many different classes of objects. Applying summary() to an lm object such as lin.model returns the key components of the regression results needed for statistical inference: estimates for the coefficients (along with their SE’s, \(t\)-statistics and the \(p\)-values), and components of the ANOVA table needed to assess the overall goodness of fit.
summary(lin.model)##
## Call:
## lm(formula = Y.2016 ~ Y.2012, data = election50)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.079300 -0.022713 0.000465 0.019404 0.061641
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.02235 0.02148 -1.041 0.303
## Y.2012 0.95295 0.04364 21.838 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.03152 on 48 degrees of freedom
## Multiple R-squared: 0.9086, Adjusted R-squared: 0.9066
## F-statistic: 476.9 on 1 and 48 DF, p-value: < 2.2e-16But before we conduct our statistical tests, we need to evaluate our model diagnostics, to make sure that the assumptions needed for valid statistical inference are met. The main assumptions concern the distribution of the residuals: that they are Normally distributed around \(0\), with uniform variance (“homoscedasticity”) and no obvious patterns or trends that suggest deviations from linearity.